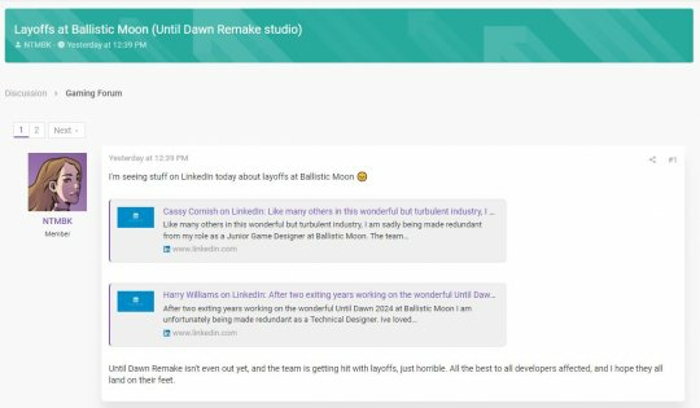
5月29日,斯坦福一AI团队发布了一个名为Llama3-V的多模态大模型,宣称只需500美元就可训练出一个性能可与GPT4-V媲美的模型。但随后,该团队发布的模型被指抄袭,其与国内清华系大模型相似度极高。面壁智能CEO李大海和联合创始人刘知远先后发文回应,表示这是一种受到国际团队认可的方式,但希望大家共建开放、合作、有信任的社区环境。目前,该团队已公开道歉,并删除了相关库和官宣推文。
斯坦福AI团队抄袭,成员公开道歉
斯坦福大学AI团队在2024年5月29日发布了一个名为Llama3-V的多模态大模型,声称只需500美元就能训练出一个性能可与GPT4-V媲美的模型。Llama3-V不仅在社交媒体上迅速蹿红,还一度冲上了HuggingFace趋势榜首页。
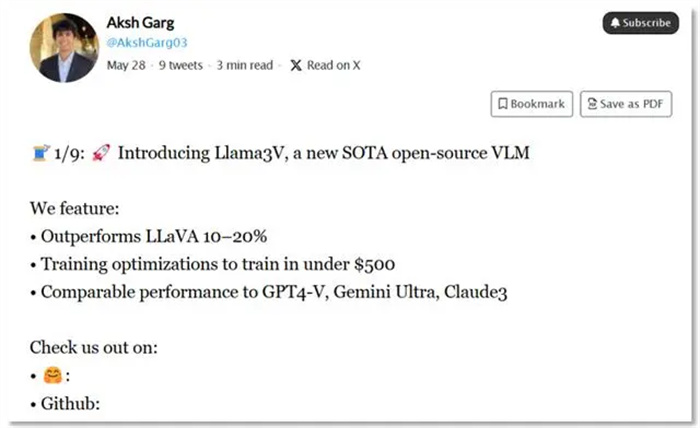
图片来源:X
然而,一名细心且热心的网友发现,该团队发布的Llama3-V和国内大模型MiniCPM-Llama3-V 2.5有极高的相似度,后者是由国内大模型初创企业“面壁智能”和清华大学自然语言处理实验室联合推出的。
网友还在在面壁智能GitHub的项目下放出了一系列证据。
该网友表示,这两个模型的结构、代码、配置文件都一模一样,只有变量名被替换了。
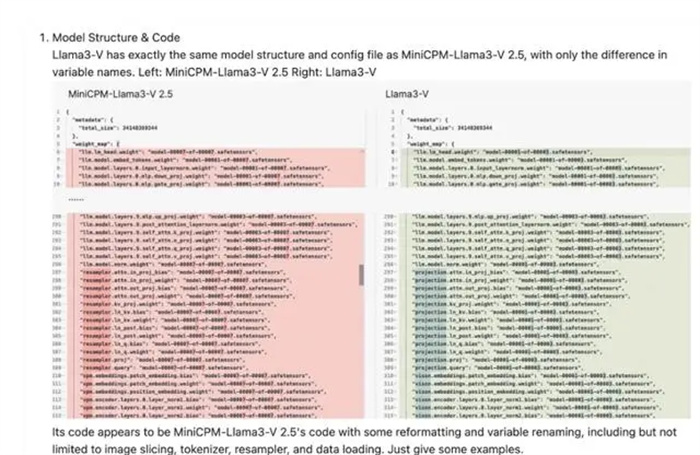
两个模型的代码对比图片来源:GitHub
随后,面壁智能首席科学家、清华大学长聘副教授刘知远在知乎上回应,MiniCPM-Llama3-V 2.5在研发时内置了一个彩蛋,就是对“清华简”的识别能力,而Llama3-V模型居然也有一模一样的能力。
清华简是清华大学于2008年7月收藏的一批战国竹简,为战国中晚期文物。刘知远透露,识别清华简是MiniCPM-Llama3-V 2.5的一项实验功能,训练图像是最近从出土文物中扫描并标注,且尚未公开发布。
关键性证据这不就来了!

图片来源:知乎
而两个模型在识别的表现上,正确的结果上基本一致,错误的情况也颇为相似。
遭到大量质疑后,该斯坦福团队成员已删除他们在X上官宣模型的推文,并将该项目在Github和HuggingFace上的库一并删除。
图片来源:X
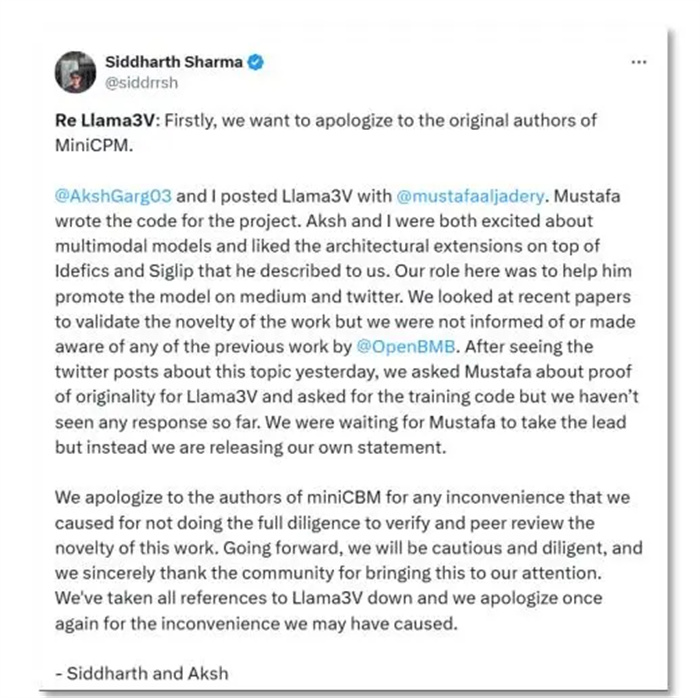
最新消息,4日,斯坦福Llama3-V团队的两位作者森德哈斯·沙玛(Siddharth Sharma)和阿克沙·加格(Aksh Garg)在社交平台上就这一学术不端行为向面壁MiniCPM团队正式道歉,并表示会将Llama3-V模型悉数撤下。
阿克沙表示,“首先,我们要向MiniCPM原作者道歉。我、森德哈斯·沙玛,以及穆斯塔法(Mustafa)一起发布了Llama3-V,穆斯塔法为这个项目编写了代码,但从昨天起就无法联系他。我与森德哈斯·沙玛主要负责帮助穆斯塔法进行模型推广。我们俩查看了最新的论文,以验证这项工作的新颖性,但并未被告知或意识到OpenBMB(清华团队支持发起的大规模预训练语言模型库与相关工具)之前的任何工作。我们向作者道歉,并对自己没有努力验证这项工作的原创性感到失望。我们对所发生的事情承担全部责任,并已撤下Llama3-V,再次致歉。”
此外,斯坦福人工智能实验室主任克里斯托弗·大卫·曼宁(Christopher David Manning)也发文谴责这一抄袭行为。
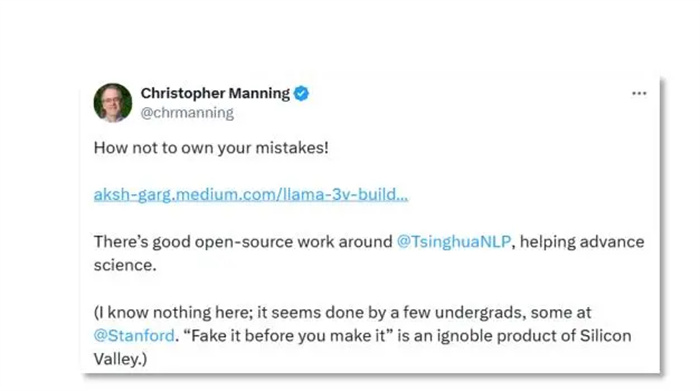
图片来源:X
面壁智能回应:“技术创新不易”“深表遗憾”
据第一财经报道,6月3日,面壁智能CEO李大海及其联合创始人刘知远相继公开发声,就他们公司的开源模型被斯坦福大学AI团队疑似抄袭的问题作出了回应。
李大海在声明中表达了对此事的深切遗憾,并指出,尽管从某种程度上看,这种模仿可以被视为他们的成果得到了国际团队的某种认可,但他更强调应该构建一个开放、协作且充满信任的技术社区环境。他进一步强调,他们希望团队的努力和优秀工作能够吸引更多人的关注和认可,但并非以这种被模仿甚至抄袭的方式。

图片来源:第一财经
面壁智能首席科学家、清华大学长聘副教授刘知远也表示,人工智能的飞速发展离不开全球算法、数据与模型的开源共享,让人们始终可以站在SOTA的肩上持续前进。面壁开源的MiniCPM-Llama3-V 2.5就用了最新的Llama3作为语言模型基座。而开源共享的基石是对开源协议的遵守,对其他贡献者的信任,对前人成果的尊重和致敬,Llama3-V团队无疑严重破坏了这一点。他们在受到质疑后已在Huggingface删库,该团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉。
天眼查APP显示,北京面壁智能科技有限责任公司成立于2022年8月,法定代表人为曾国洋,董事长为李大海,注册资本约52.46万人民币,经营范围包括软件开发、人工智能基础软件开发、人工智能理论与算法软件开发、信息系统集成服务等。股东信息显示,该公司由北京清语启航科技中心(有限合伙)、曾国洋、李大海等共同持股。知识产权信息显示,该公司已申请了多项专利,如“基于人工智能自适应的NLP大模型分析系统”“深度学习模型统一应用方法、装置、服务器及存储介质”“基于人工智能的对话预测方法、装置及存储介质”,当前部分专利已获授权。此外,该公司还登记了“CPM模型能力展示平台”“面壁智能模力表格文本生成系统”等多个软件著作权。
面壁智能目前已完成两轮融资。去年4月,公司完成由知乎、智谱AI投资的数千万人民币天使轮融资;今年4月,公司宣布完成新一轮数亿元融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。
据其官网显示,面壁智能联合创始人、CEO李大海,硕士毕业于北京大学数学系,毕业后加入Google,成为Google中国创始员工之一,后在云云网任工程总监,在豌豆荚任搜索技术负责人,连续12年创业经验。2015年加入知乎,任知乎合伙人、CTO。
面壁智能联合创始人、首席科学家刘知远,是清华大学计算机系长聘副教授,智源青年科学家。主要研究方向为自然语言处理、知识图谱和社会计算。在人工智能领域著名国际期刊和会议发表相关论文200余篇,Google Scholar统计引用超过3.1万次。曾获教育部自然科学一等奖、中国中文信息学会钱伟长中文信息处理科学技术奖一等奖、入选国家青年人才计划、《麻省理工科技评论》中国区35岁以下科技创新35人榜单。

图片来源:面壁智能官网
每日经济新闻综合第一财经、公开消息
每日经济新闻
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人,本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任,如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 346067576@qq.com 或拨打客服电话:13043476030举报,一经查实,本站将立刻删除。